

Deep Engineering #54: Sibasis Padhi on Governing Agentic Operations Before They Amplify Failures
Actuation budgets, blast radius, and the reversibility that stops self-healing from becoming self-harm


ARC 2026: Software Architecture in the Age of AI
Packt’s flagship two-day virtual summit

AI is reshaping software architecture, putting new demands on scalability, governance, reliability, and observability. ARC 2026 brings together architects, CTOs, and AI practitioners for keynotes, panels, and workshops on agentic system design, modernizing enterprise apps for AI, and building governable, observable AI systems.
The lineup includes Dr. Ali Arsanjani (Director, Applied AI, Google), David Ping (Head of Solutions Architecture, AWS), and Chi Wang (Google DeepMind), alongside other notable leaders distilling practical insights.
🗓️ 25 to 26 July, 10:30 am ET
Use code DEEPENG50 for 50% off the early bird price.
✍️ From the editor’s desk,
Welcome to the 54th issue of Deep Engineering!
Site reliability engineering is already agentic, and agents are moving from the edges of the incident into its core. New Relic unveiled Autopilot at its New Relic NOW event on June 23, an automated SRE agent that triages incidents, identifies root causes, and scopes remediations the moment an alert fires. “Operations are going headless,” said New Relic’s Head of AI, Camden Swita, describing agents that pull what they need through APIs and act.
That is exactly when governance starts to matter more than speed. Once an agent can decide and push a remediation, the reliability question is no longer whether automation moves fast but whether its actions stay bounded. Faster, wider change across a tightly coupled system amplifies trouble as easily as it absorbs it, and the retry, scaling, and routing reflexes that steady a healthy platform can drive a cascade once it is already stressed. Tellingly, even these launches arrive wrapped in the language of guardrails and human review.
The engineers who feel that trade-off most work where a wrong automated action shows up immediately on the balance sheet. Sibasis Padhi, a Staff Software Engineer at Walmart Global Tech, builds large-scale financial platforms of exactly that kind. In his Deep Engineering article “Autonomic Governance for Agentic Systems,” he argues that reliability engineering must evolve from managing distributed systems to governing the automation that manages them.
Padhi makes the case that the fix is not less automation but automation you can bound, audit, and reverse.
Let’s get started.
Featured Newsletter: The Hustling Engineer

Read by 25,000+ software engineers, The Hustling Engineer covers career growth, AI, interviews, and productivity. Every week you get actionable insights, engineering deep dives, and lessons from top tech companies.
📩 Get one actionable lesson every week to accelerate your tech career.
→ Subscribe to The Hustling Engineer
🧠 Expert Insight
Autonomic Governance for Agentic Systems
The incident often starts small. Usually one dependency slows, tail latency grows, and a few requests time out. And then the platform does what we trained it to do. All the while, customers automatically retry their failed requests, and very quickly there are far more retry attempts than real new customers trying to use the service. But the autoscaling system sees the growing queue and reads it as exploding traffic, so it adds more servers, often in the wrong place, which sends even more work to the spot that is already overloaded.
This eats into the bottom line and the return on engineering investment as the bill keeps mounting while the system handles less real work. Circuit breakers finally trip and try to move traffic elsewhere, but those other paths were never built to absorb a sudden flood.
Everything might still look like it is working on paper, but the whole situation keeps getting worse. Now compound that by adding agentic AI to operations, systems that recommend or execute operational actions, which increases the speed and breadth of change under conditions that are already chaotic.
AI-driven operational automation can increase fragility when it increases the rate, scope, or coupling of production actions without bounded actuation, explicit constraints, and auditability. Under governance, the same automation reduces fragility by enforcing safety envelopes and reversible decision paths.
This is not an argument against automation or AI. It is an argument that reliability engineering must evolve from managing distributed systems to governing the automation that manages them, especially under simultaneous SLO, cost, and compliance constraints. I call this discipline Autonomic Reliability Governance (ARG). ARG is not more automation. But governed automation that is policy-constrained, auditable, and rollback-capable by design. It ensures that AI-assisted or agentic operational decisions cannot escalate into amplification engines under stress.
Why reliability automation amplifies in microservice ecosystems
In microservice systems, outages rarely come from a single broken component. They emerge from how services interact, through feedback loops, dependencies, and cascading effects. Mechanisms that improve reliability in normal conditions can unintentionally amplify problems when the system is already under stress, which is the feedback behavior Karl Johan Åström and Richard Murray formalize in Feedback Systems (Princeton University Press, 2008).
Retries multiply load under stress
Retries improve success rates when failures are transient and capacity is available. Under degradation, retries become a multiplier, the dynamic Jeffrey Dean and Luis André Barroso describe in “The Tail at Scale” (Communications of the ACM, February 2013).
A dependency slows → timeouts increase → retries surge → downstream work increases → queues grow → latency rises → more timeouts → more retries.
This is how a minor regression becomes a self-inflicted flood. It can resemble a resource exhaustion event even when there is no attacker. The mechanism is simple. Unbounded retries consume the remaining capacity of an already-constrained dependency. The root issue is not that retries are bad. The issue is that unbounded retries are a powerful actuator that must be governed by system-level constraints such as SLO, cost, and blast radius.
Autoscaling is a blunt actuator fed by ambiguous signals
Autoscaling adds or removes capacity based on signals like CPU usage, request rate, or queue length. During incidents those signals mislead. Queue depth may grow because a dependency is slow, not because demand has grown. CPU may spike from retries and timeouts, not real workload. Request rates may rise simply because retried calls look like new traffic. A reactive autoscaler then adds capacity in the wrong place, driving up cost while putting even more pressure on the real bottleneck. The result is a system that becomes less stable and more expensive at exactly the moment it needs to recover.
Circuit breakers carry shock-wave potential
Circuit breakers are necessary. Without system-level coordination they create abrupt traffic shocks. If multiple clients trip simultaneously, alternate paths overload and create secondary failures that appear unrelated to the original degradation.
The common pattern is unbounded actuation in a coupled system
Retries, autoscaling, and circuit breakers are not mistakes. They are essential reliability tools. Problems arise when they operate like independent reflexes, without coordination or limits. When nothing controls how often they act, how broadly their actions affect the system, how easily changes can be reversed, or how clearly decisions can be explained, they unintentionally amplify failures. Managing this was already difficult with manually written rules. It becomes even more critical when AI agents make or trigger operational decisions.
Why agentic operations change the physics
Traditional automation such as scripts, thresholds, and fixed policies is limited in scope and relatively legible. Agentic systems expand both capability and risk because they tend to:
Increase velocity: propose actions faster than humans can validate non-local effects.
Increase scope: coordinate actions across services, clusters, and regions.
Optimize proxies: Charles Goodhart warned in 1975 that a statistical regularity tends to collapse once it is used as a control target, a caution later popularized as “when a measure becomes a target, it ceases to be a good measure” (”Problems of Monetary Management: The U.K. Experience,” 1975). Optimizing latency or cost in isolation can degrade reliability unless constraints are explicit.
Operate under uncertainty: incidents produce ambiguous signals, and partial telemetry invites misdiagnosis and overcorrection.
Reduce legibility unless designed otherwise: without decision traces, you cannot reconstruct why the system acted or demonstrate compliance.
So the risk is not AI in isolation. The risk is unbounded actuation under uncertainty. ARG is the discipline designed to make agentic operations governable.
A practical lens on amplification
To manage automation safely, teams need a clear way to recognize when helpful mechanisms start making things worse. Amplification is that lens. A reliability mechanism helps when it improves outcomes without adding too much extra load. It becomes harmful when it multiplies load, volatility, or system-wide effects beyond what the platform can handle. In practice, retries multiply request volume, autoscaling multiplies capacity changes and cost, traffic shifts increase pressure on dependencies, and aggressive fixes create configuration churn. ARG is essentially the discipline of keeping these amplification effects under control.
Autonomic Reliability Governance governs the automation itself
The notion that systems can manage themselves is not new. Jeffrey Kephart and David Chess articulated that aspiration more than two decades ago in “The Vision of Autonomic Computing” (IEEE Computer, January 2003). What is new is the velocity and scope of actuation introduced by agentic AI. Autonomic Reliability Governance is the discipline of designing and operating bounded, auditable, and reversible automation, including agentic operational decision layers, under explicit constraints.
SLO constraints: latency ceilings, availability targets, error budgets.
Cost constraints: budget caps, unit-economics bounds, runaway scaling prevention.
Compliance constraints: auditability of decisions and actions.
ARG is not a product. It is an operating model, automation you can trust because it is governable. ARG treats operational actuation, human or agentic, as a first-class risk surface with explicit safety envelopes..
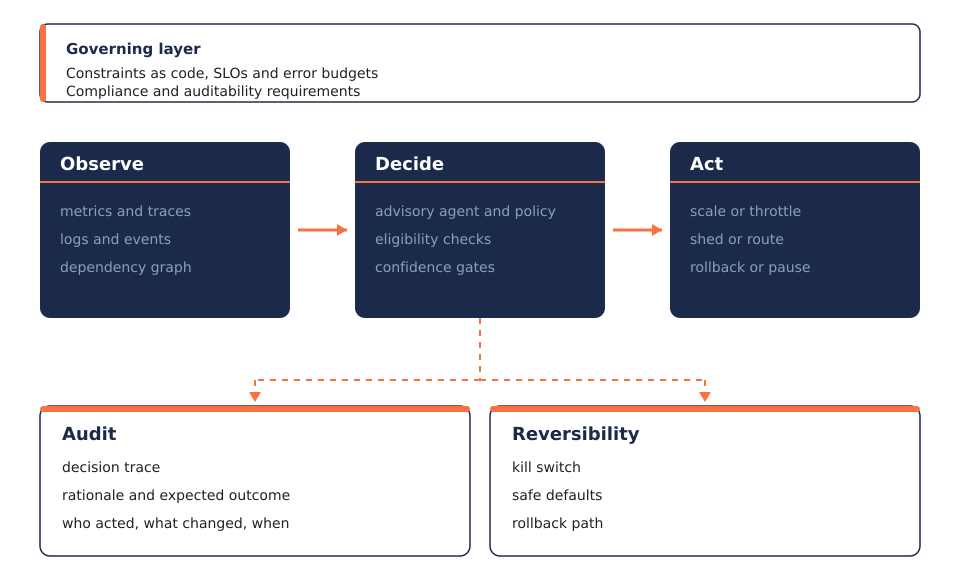
Governance primitives that make agentic operations safe
ARG becomes real when it is implemented through governance primitives that align with existing reliability practice such as SLOs, error budgets, and progressive rollout, while controlling actuation velocity and blast radius.
1) Actuation budgets rate-limit change, not only traffic
Most systems rate-limit user requests. Few rate-limit operational change. ARG introduces actuation budgets, limits on how frequently high-impact actions can occur. Scaling shifts, retry escalations, routing changes, and configuration flips consume tokens from a constrained budget. When the budget is exhausted, automation may still observe and recommend, but it cannot repeatedly perturb the system. When instability rises, slow the actuators before adding more intelligence.
2) Blast radius governance scopes every action
The difference between a safe fix and an outage multiplier is often scope. ARG constrains blast radius using canaries, segmentation across cells and regions, tiered permissions, and scoped rollouts with automatic halt conditions. Even correct actions can be wrong if applied globally in one step. Autonomy must always be localized before it is generalized.
Continue reading - the seven governance primitives that turn ARG from principle into practice, how to validate governed automation without touching production or private data, and why agentic operations win by becoming more governable, not more intelligent.
Autonomic Governance for Agentic Systems

Sibasis Padhi on the discipline of bounding, auditing, and reversing agentic operational decisions so automation dampens incidents instead of amplifying them.
🛠️ Tool of the Week
Argo Rollouts - a progressive delivery controller for Kubernetes
Highlights:
Bounds blast radius by exposing a change to a small traffic slice first, closing the gap that standard rolling updates leave open where nothing limits exposure or triggers an automated rollback on failure.
Makes reversibility the default, since a rollback shifts traffic back to the previous version instead of triggering a fresh deploy.
Gates promotion on evidence rather than a timer, aborting automatically when success rate or latency crosses a threshold, which mirrors the confidence gates in the feature.
Fits GitOps workflows, where an automatic rollback surfaces as divergence from declared state and prompts investigation before anyone retries.
📎 Tech Briefs
Google makes Model Armor generally available for Agent Gateway - Model Armor reaches general availability for Agent Gateway, screening agent prompts and responses against content guardrails.
Datadog extends Bits AI to autonomous remediation at DASH - Bits AI now detects and remediates autonomously within predefined guardrails, and Agent Console tracks agent actions.
OpenTelemetry graduates from the CNCF - OpenTelemetry graduates from the CNCF, cementing the vendor-neutral telemetry standard that grounds agent decisions in trusted context.
Microsoft makes Azure SRE Agent generally available - Azure SRE Agent is generally available, with Review and Autonomous run modes gating remediation behind human approval.
Grafana previews AI Observability in Grafana Cloud - Grafana previews AI Observability, treating agent sessions as first-class telemetry and alerting on policy violations and anomalies.
That’s all for today. Thank you for reading this issue of Deep Engineering.
We’ll be back next week with more expert-led content.
Keep building,
Saqib Jan
Editor-in-Chief, Deep Engineering
If your company wants to reach senior developers, software engineers, and technical decision-makers, speak to us about partnering with Deep Engineering.
 | A guest post by
|