

The incident often starts small. Usually one dependency slows, tail latency grows, and a few requests time out. And then the platform does what we trained it to do. All the while, customers automatically retry their failed requests, and very quickly there are far more retry attempts than real new customers trying to use the service. But the autoscaling system sees the growing queue and reads it as exploding traffic, so it adds more servers, often in the wrong place, which sends even more work to the spot that is already overloaded.
This eats into the bottom line and the return on engineering investment as the bill keeps climbing while the system handles less real work. Circuit breakers finally trip and try to move traffic elsewhere, but those other paths were never built to absorb a sudden flood.
Everything might still look like it is working on paper, but the whole situation keeps getting worse. Now compound that by adding agentic AI to operations, systems that recommend or execute operational actions, which increases the speed and breadth of change under conditions that are already chaotic.
AI-driven operational automation can increase fragility when it increases the rate, scope, or coupling of production actions without bounded actuation, explicit constraints, and auditability. Under governance, the same automation reduces fragility by enforcing safety envelopes and reversible decision paths.
This is not an argument against automation or AI. It is an argument that reliability engineering must evolve from managing distributed systems to governing the automation that manages them, especially under simultaneous SLO, cost, and compliance constraints. I call this discipline Autonomic Reliability Governance (ARG). ARG is not more automation. But governed automation that is policy-constrained, auditable, and rollback-capable by design. It ensures that AI-assisted or agentic operational decisions cannot escalate into amplification engines under stress.
Why reliability automation amplifies in microservice ecosystems
In microservice systems, outages rarely come from a single broken component. They emerge from how services interact, through feedback loops, dependencies, and cascading effects. Mechanisms that improve reliability in normal conditions can unintentionally amplify problems when the system is already under stress, which is the feedback behavior Karl Johan Åström and Richard Murray formalize in Feedback Systems.
Retries multiply load under stress
Retries improve success rates when failures are transient and capacity is available. Under degradation, retries become a multiplier, the dynamic Jeffrey Dean and Luis André Barroso describe in “The Tail at Scale”.
A dependency slows → timeouts increase → retries surge → downstream work increases → queues grow → latency rises → more timeouts → more retries.
This is how a minor regression becomes a self-inflicted flood. It can resemble a resource exhaustion event even when there is no attacker. The mechanism is simple. Unbounded retries consume the remaining capacity of an already-constrained dependency. The root issue is not that retries are bad. The issue is that unbounded retries are a powerful actuator that must be governed by system-level constraints such as SLO, cost, and blast radius.
Autoscaling is a blunt actuator fed by ambiguous signals
Autoscaling adds or removes capacity based on signals like CPU usage, request rate, or queue length. During incidents those signals mislead. Queue depth may grow because a dependency is slow, not because demand has grown. CPU may spike from retries and timeouts, not real workload. Request rates may rise simply because retried calls look like new traffic. A reactive autoscaler then adds capacity in the wrong place, driving up cost while putting even more pressure on the real bottleneck. The result is a system that becomes less stable and more expensive at exactly the moment it needs to recover.
Circuit breakers carry shock-wave potential
Circuit breakers are necessary. Without system-level coordination they create abrupt traffic shocks. If multiple clients trip simultaneously, alternate paths overload and create secondary failures that appear unrelated to the original degradation.
The common pattern is unbounded actuation in a coupled system
Retries, autoscaling, and circuit breakers are not mistakes. They are essential reliability tools. Problems arise when they operate like independent reflexes, without coordination or limits. When nothing controls how often they act, how broadly their actions affect the system, how easily changes can be reversed, or how clearly decisions can be explained, they unintentionally amplify failures. Managing this was already difficult with manually written rules. It becomes even more critical when AI agents make or trigger operational decisions.
Why agentic operations change the physics
Traditional automation such as scripts, thresholds, and fixed policies is limited in scope and relatively legible. Agentic systems expand both capability and risk because they tend to:
Increase velocity: propose actions faster than humans can validate non-local effects.
Increase scope: coordinate actions across services, clusters, and regions.
Optimize proxies: Charles Goodhart warned in 1975 that a statistical regularity tends to collapse once it is used as a control target, a caution later popularized as “when a measure becomes a target, it ceases to be a good measure” (Problems of Monetary Management: The U.K. Experience). Optimizing latency or cost in isolation can degrade reliability unless constraints are explicit.
Operate under uncertainty: incidents produce ambiguous signals, and partial telemetry invites misdiagnosis and overcorrection.
Reduce legibility unless designed otherwise: without decision traces, you cannot reconstruct why the system acted or demonstrate compliance.
So the risk is not AI in isolation. The risk is unbounded actuation under uncertainty. ARG is the discipline designed to make agentic operations governable.
A practical lens on amplification
To manage automation safely, teams need a clear way to recognize when helpful mechanisms start making things worse. Amplification is that lens. A reliability mechanism helps when it improves outcomes without adding too much extra load. It becomes harmful when it multiplies load, volatility, or system-wide effects beyond what the platform can handle. In practice, retries multiply request volume, autoscaling multiplies capacity changes and cost, traffic shifts increase pressure on dependencies, and aggressive fixes create configuration churn. ARG is essentially the discipline of keeping these amplification effects under control.
Autonomic Reliability Governance governs the automation itself
The notion that systems can manage themselves is not new. Jeffrey Kephart and David Chess articulated that aspiration more than two decades ago in “The Vision of Autonomic Computing”. What is new is the velocity and scope of actuation introduced by agentic AI. Autonomic Reliability Governance is the discipline of designing and operating bounded, auditable, and reversible automation, including agentic operational decision layers, under explicit constraints.
SLO constraints: latency ceilings, availability targets, error budgets.
Cost constraints: budget caps, unit-economics bounds, runaway scaling prevention.
Compliance constraints: auditability of decisions and actions.
ARG is not a product. It is an operating model, automation you can trust because it is governable. ARG treats operational actuation, human or agentic, as a first-class risk surface with explicit safety envelopes.
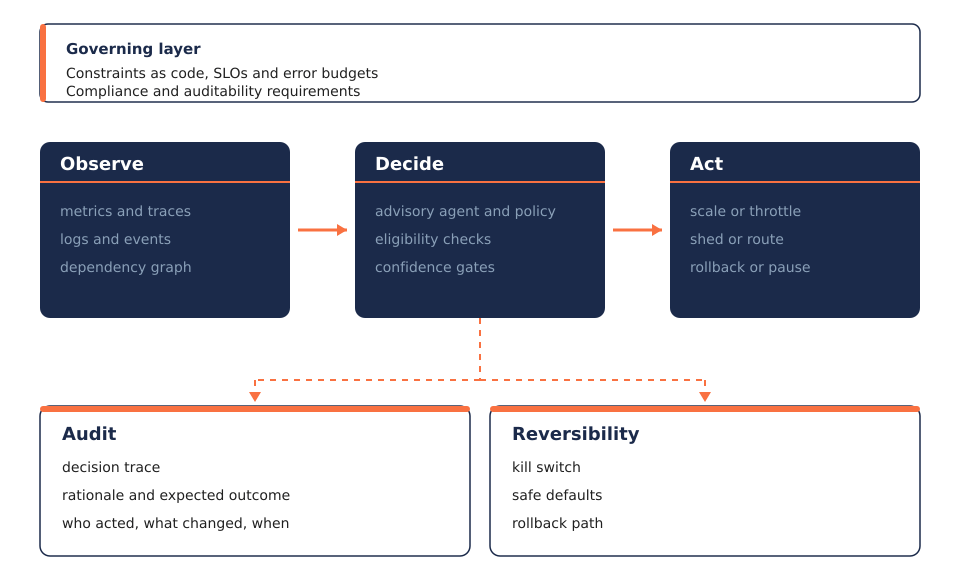
Governance primitives that make agentic operations safe
ARG becomes real when it is implemented through governance primitives that align with existing reliability practice such as SLOs, error budgets, and progressive rollout, while controlling actuation velocity and blast radius.
1) Actuation budgets rate-limit change, not only traffic
Most systems rate-limit user requests. Few rate-limit operational change. ARG introduces actuation budgets, limits on how frequently high-impact actions can occur. Scaling shifts, retry escalations, routing changes, and configuration flips consume tokens from a constrained budget. When the budget is exhausted, automation may still observe and recommend, but it cannot repeatedly perturb the system. When instability rises, slow the actuators before adding more intelligence.
2) Blast radius governance scopes every action
The difference between a safe fix and an outage multiplier is often scope. ARG constrains blast radius using canaries, segmentation across cells and regions, tiered permissions, and scoped rollouts with automatic halt conditions. Even correct actions can be wrong if applied globally in one step. Autonomy must always be localized before it is generalized.
3) Advisory-first agents and progressive autonomy
In high-stakes systems, autonomy should begin as advisory. Agents recommend and humans approve. As evidence accumulates and safety is demonstrated, constrained autonomy can expand within defined envelopes.
4) Eligibility tiers put permission models over personality
Autonomy must be governed by explicit action tiers:
Observational: detection and diagnosis, always allowed.
Low-risk reversible actions: scoped and rollback-capable.
Medium-risk actions: require high confidence and strict guardrails.
High-risk actions: require human approval.
Autonomy becomes measurable when agents must graduate across tiers based on demonstrated safety.
5) Confidence gates and evidence before execution
Agents should act only when evidence crosses defined thresholds:
sufficient telemetry completeness
credible dependency attribution
system stability signals
reversibility guarantees
bounded failure domain
If uncertainty is high, remain advisory.
6) Auditability makes the decision trace a first-class artifact
Governed autonomy requires structured decision records:
what was observed
what was concluded, with uncertainty
what constraints were evaluated
what action was taken or recommended
what was expected
what occurred
how it can be reversed
Auditability is not bureaucracy. It is what enables learning, compliance, and safe expansion of autonomy.
7) Reversibility means designing for wrong decisions
Every operational action must have an undo path. Rollbacks, kill switches, and safe defaults are mandatory. Governance does not prevent all mistakes. It ensures failures stay bounded and recoverable.
Validating governance without private company data
ARG also needs ways to test ideas without using private company data. One practical approach is incident replay. You capture common failure patterns such as latency spikes, growing queues, retry storms, or autoscaling reactions, and replay them in a simulation or controlled environment. Then you compare how the system behaves under unbounded automation versus governed policies, and you check whether the changes reduce amplification or make it worse. The goal is not to perfectly recreate production, but to learn in a measurable way, so the question is whether a policy dampens instability or accelerates it. This can be reinforced with controlled stability drills such as dependency injection, brownouts, or chaos experiments, the practice Ali Basiri and colleagues describe in “Chaos Engineering” (IEEE Software, May 2016), so that automation stays controlled when conditions degrade.
What changes when ARG becomes normal practice
As systems become more autonomous, reliability work will increasingly focus on governing automation itself. That means turning constraints into enforceable policies, limiting and scoping automated actions, treating audit trails as essential system outputs, and introducing autonomy gradually rather than all at once. FinTech-scale platforms are likely to adopt this approach early because reliability targets, cost limits, and audit requirements are strict, and failures are expensive. In the end, agentic operations will not succeed simply by becoming more intelligent. They will succeed by becoming more governable.
Do not automate reliability, govern automation
Retries and autoscaling will remain foundational, and AI will increasingly enter operations. The question is whether these mechanisms amplify failures or dampen them. If we bolt AI onto production as an unbounded actuator, we create faster cascades and more expensive incidents. If we treat autonomy as a governed system that is bounded, auditable, and reversible, we can build platforms that are both resilient and efficient. Autonomic Reliability Governance is a practical blueprint for getting there.
Acknowledgements and disclosures by the Author
Submitted by Sibasis Padhi.
Generative AI tools and Grammarly were used to assist with drafting and English corrections. The author reviewed, revised, and assumes full responsibility for the final content.
About Sibasis

Sibasis Padhi is a Staff Software Engineer at Walmart Global Tech with more than 18 years building and optimizing large-scale enterprise systems, including cloud-native financial platforms that handle high-volume transactions. His work centers on microservices performance, observability, distributed systems reliability, and agentic AI. He speaks at IEEE conferences and industry events on resilient financial systems and agentic operations.