

Deep Engineering #52: Sam Keen on the Context Tax You Pay in Every Claude Code Session
Why every AI coding session starts from zero, and how to fix it with a system instead of a better prompt


Claude Code for Software Engineering

Join this interactive workshop to learn how to turn Claude Code from a session-by-session assistant into a repeatable engineering system, using structured context, reusable skills, scoped rules, hooks, and guardrails that work across real codebases and team workflows.
🗓️ Friday, June 20 · 10:30 AM EDT onwards
Use code DEEPENG50 for 50% off.
✍️ From the editor’s desk,
Welcome to the 52nd issue of Deep Engineering!
A recent study pulled apart the architecture of Claude Code and found that only 1.6 percent of the codebase is actual AI decision logic, while the remaining 98.4 percent is the deterministic infrastructure that surrounds the model, including the permission gates, the context management, the tool routing, and the recovery logic that keep the whole thing usable. The agent loop at the center of it turns out to be a simple while loop, which means the genuine engineering effort sits in the systems built around the model rather than in the model itself.
This analysis lines up almost exactly with what most engineers working with AI tools are discovering through daily practice, which is that the thing slowing them down is rarely the intelligence of the model and is far more often the fact that none of the context they carefully supply in one session survives into the next. Supplying that missing context has quietly become the engineer’s job, and it gets paid at the start of every single session without anyone ever counting it.
This week Sam Keen, an agentic engineering researcher, and former engineer at AWS and Nike, and the author of Clean Architecture with Python, shares a practical way to stop paying that cost for good. His piece walks through how to convert the context you re-explain on repeat into a system that compounds across sessions, using the mechanisms Claude Code already gives you, and how to recognize the moment that system starts quietly working against you rather than for you.
Let’s get started.
Featured Newsletter: Engineering At Scale

A weekly column that makes databases, system design, and architecture easy to follow, with clear explanations, practical insights, and career advice for engineers building at scale.
→ Subscribe to Engineering At Scale
The Hidden Cost of Starting From Scratch
Submitted by Sam Keen
When you open a fresh Claude Code session, the assistant knows nothing about your project. It does not know where your tests live, it does not know the patterns this codebase uses, and it does not remember the conventions you walked it through the day before. So you explain all of it again, and then you do the same thing again tomorrow.
That re-teaching is a tax, and it is the easiest one to overlook because it never shows up on any gauge, which means you pay it at the start of every session without ever once counting what it costs you.
The bottleneck isn’t the model
The real limiting factor in AI-assisted development right now is not how clever the model is, because the models are already more than capable enough for the work most teams are asking of them. The limiting factor is that none of that intelligence carries from one session into the next, and the job of supplying the missing context every single time has quietly been handed to you without anyone naming it as work.
Picture a senior engineer who forgets everything about your codebase overnight, every single night, and shows up the next morning brilliant and fast and genuinely helpful but starting again from absolute zero. You would not describe that person as a force multiplier, you would describe the arrangement as exhausting, and yet that is the default relationship most people have with their coding assistant. They end up blaming the model for the drag when the actual problem is that nothing they explained yesterday is still present today.
Write the context down once
The fix is to stop starting from scratch, which means writing the recurring context down once in a place the harness reads automatically so that it is present in every session without you having to lift a finger. Claude Code gives you several mechanisms for doing exactly this, and three of them are foundational. The most useful way to think about the three is by the specific kind of cost each one removes from your day.
Agent files, written as CLAUDE.md, are your project’s standing memory, the place where the conventions and the layout and the way things get done here all live. You write them once and they load into every session, so you stop re-explaining the project from the beginning each time. The part most people underuse is that these files load hierarchically, which means a personal file can ride along on every session on your machine, a broader file can cover all of your coding work, and a project-specific file can sit on top of both, each one layering onto the last. The thing to remember is to keep them lean, somewhere around a couple hundred lines each rather than letting them sprawl.
Skills capture the procedures you would otherwise walk through by hand every time, the multi-step moves where you first do one thing and then check another before continuing. A procedure you would normally re-explain becomes a procedure you simply invoke, and because a skill is not limited to instructions alone, it can bundle the scripts the agent runs, which means the repeatable move can carry real executable code rather than prose describing what the code should do.
Hooks handle the corrections you would otherwise find yourself repeating, the lint nit and the formatting rule and the check you keep having to ask for. They fire at fixed points in the harness lifecycle, before or after a tool runs for instance, and because they sit outside the model’s control they run every single time regardless of whether the model would have remembered to do them. You give the note once and then you never have to give it again.
The pattern underneath all three mechanisms is the same one, because each of them converts a recurring cost into a single one-time write. That is what compounding actually means in this context, and it is the direct opposite of starting from scratch, since the investment you make is small and the payback lands in every session that follows it.
Your setup can rot, here is how to catch it
There is an honest catch worth naming here, and it is the place where the /context command earns its keep, because a compounding system can quietly rot over time. You install a skill pack and then forget it is even there. A CLAUDE.md that started out tight slowly fills up with things that mattered once and no longer do. The investment turns into freight without you noticing, and freight is really just the from-scratch tax wearing a slightly nicer costume.
The /context command is how you tell the difference, and it does one genuinely useful thing, which is that it makes the invisible visible. One command gives you a colored grid and a per-category breakdown of exactly what you are carrying before the conversation has even started. You do not need to master it, you only need to glance at it often enough to notice when something is wrong.
The last time I ran it, the single biggest chunk of my standing context was not the project memory I had carefully written, it was 14.4k tokens of skill packs I had installed on a whim and then never used even once. I had assumed my context was quietly working in my favor, and a five-second look told me otherwise. Culling them took about a minute, using /skills to deactivate the ones I never reach for and /plugin to drop a whole pack that had arrived bundled with something else.
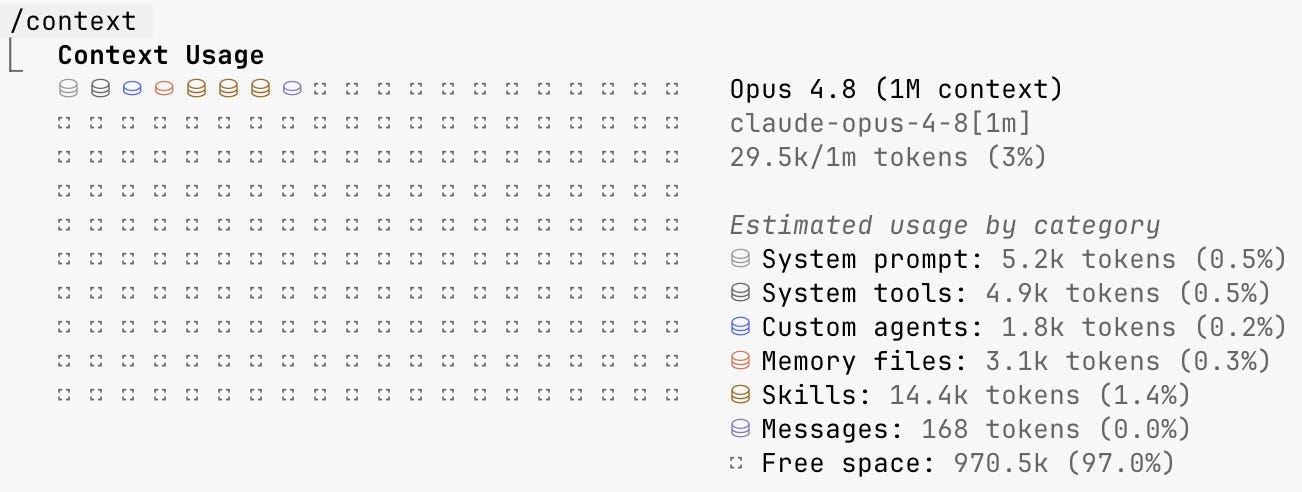
That same readout flagged a second problem with a different fix, because the CLAUDE.md in my working directory had grown to 3,500 tokens without my noticing. I sat down with Claude and compacted it, cutting the irrelevant and the quietly duplicated, and it came back at 1,200 tokens, which is the same project memory carried at roughly a third of the weight.

Clarity helps the agent for exactly the same reason it helps a human reader, because a bloated and half-contradictory CLAUDE.md does not only cost you tokens, it actively muddies the very instructions you are leaning on to get good work out of the model. A lean file is easier for the model to follow in the same way that a tight brief is easier for a colleague to follow.
The specific number you land on does not really matter, but the habit does, so skim /context the way you would skim a credit-card statement, not obsessively but often enough to catch the recurring charge you forgot you ever signed up for.
Do the upfront work once
Starting from scratch feels free because the cost is smeared so thin across every session you will ever run, but it is not actually free, and it is in fact one of the largest and quietest line items in the way you work.
So put in the upfront work of writing a lean memory file, building a few skills you genuinely use, and setting a couple of hooks that hold the line for you. Then keep curating it, because models change and your projects change, and a glance at /context now and then is what tells you which parts of your setup are still earning their place. The goal was never a clever prompt. The goal is a setup that already knows your project before you say a single word to it.
Ad: Join Packt’s live workshop Claude Code Beyond Prompts by Sam Keen on June 20 and learn how to turn CLAUDE.md, skills, and hooks into a compounding coding system.
Use code CLAUDE60 for 60% off. Limited to the first 10 sign-ups.
🛠️ Tool of the Week
Repomix — an open source tool that packs an entire repository into a single, AI-friendly file ready to feed to a coding agent, with token counting built in.
Highlights
Packs a whole repository into a single structured file optimized for LLM consumption, removing the manual copy-paste that eats the start of every session.
Counts tokens per file and for the whole pack, so you see what context costs before you spend it rather than after.
Ships an official skill for Claude Code, Cursor, Codex, and Copilot, letting agents run Repomix directly inside the workflow.
📎 Tech Briefs
Anthropic suspends Fable 5 and Mythos 5 worldwide - A US export control directive citing national security forced Anthropic to disable both frontier models for all customers, days after launch, with all other models unaffected.
OpenAI Codex 0.140.0 ships - Codex adds Claude Code imports, unified mentions, and encrypted Amazon Bedrock API-key authentication.
GitHub Copilot CLI 1.0.63 released - A new
deferToolsoption reduces MCP context bloat when tool search is enabled.Xiaomi open-sources MiMo Code - Xiaomi’s terminal coding agent targets long tasks and offers free limited-time MiMo Auto access.
ChatGPT adds memory summary controls - Users can delete memories, turn memory off, and directly correct their memory summary.
That’s all for today. Thank you for reading this issue of Deep Engineering.
We’ll be back next week with more expert-led content.
Keep building,
Saqib Jan
Editor-in-Chief, Deep Engineering
If your company wants to reach senior developers, software engineers, and technical decision-makers, speak to us about partnering with Deep Engineering.
 | A guest post by
|